
“Finite Field Arithmetic.” Chapter 9: "Exodus from Egypt" with Comba's Algorithm.
This article is part of a series of hands-on tutorials introducing FFA, or the Finite Field Arithmetic library. FFA differs from the typical "Open Sores" abomination, in that -- rather than trusting the author blindly with their lives -- prospective users are expected to read and fully understand every single line. In exactly the same manner that you would understand and pack your own parachute. The reader will assemble and test a working FFA with his own hands, and at the same time grasp the purpose of each moving part therein.
- Chapter 1: Genesis.
- Chapter 2: Logical and Bitwise Operations.
- Chapter 3: Shifts.
- Chapter 4: Interlude: FFACalc.
- Chapter 5: "Egyptological" Multiplication and Division.
- Chapter 6: "Geological" RSA.
- Chapter 7: "Turbo Egyptians."
- Chapter 8: Interlude: Randomism.
- Chapter 9: "Exodus from Egypt" with Comba's Algorithm.
You will need:
- All of the materials from Chapters 1 - 8.
ffa_ch9_exodus.vpatch(see here)ffa_ch9_exodus.vpatch.asciilifeform.sig- ffa_ch9_exodus.kv.vpatch
- ffa_ch9_exodus.kv.vpatch.asciilifeform.sig
Add the above vpatch and seal to your V-set, and press to ffa_ch9_exodus.kv.vpatch.
You should end up with the same directory structure as previously.
Now compile ffacalc:
cd ffacalc gprbuild |
But do not run it quite yet.
The "Egyptian" algorithm for multiplication (in its simplest Chapter 5 version, and likewise in the refined form given in Chapter 7) has a time cost that is proportional to the square of the operand bitness -- i.e. it runs in O(N^2), or quadratic time. In Chapter 10, we will meet a substantially faster -- subquadratic -- algorithm for multiplication. However, for reasons which will become apparent to the reader, we would first like to obtain the fastest quadratic-time multiplier that we possibly can (without compromising any of the FFA design principles laid out in Chapter 1).
The ancient Egyptians came up with an easily-taught and reasonably efficient-method for multiplication. However, they ran it "on" human scribes, rather than automatic machinery. And it turns out that the latter, especially in the form of recently-made CPUs, is quite sensitive to the particular time-and-space "shape" of an algorithm. But we will expand on this point later.
Mathematician and astronomer Paul G. Comba (1926 -- 2017) devised an elegant multiplication algorithm which superficially resembles the familiar "grade school" long-multiplication -- but with the important difference that it does not require the generation of intermediate per-row temporary results. Instead, it generates each column -- or digit -- (or, in FFA parlance, Word) of the product, sequentially, from lowest to highest, using only a handful of words of memory for temporary storage. Let's implement Comba's algorithm:
FZ_Mul.ads:
with FZ_Type; use FZ_Type; package FZ_Mul is pragma Pure; -- Comba's multiplier. procedure FZ_Mul_Comba(X : in FZ; Y : in FZ; XY_Lo : out FZ; XY_Hi : out FZ); pragma Precondition(X'Length = Y'Length and XY_Lo'Length = XY_Hi'Length and XY_Lo'Length = ((X'Length + Y'Length) / 2)); end FZ_Mul; |
FZ_Mul.adb:
with Words; use Words; with Word_Ops; use Word_Ops; with W_Mul; use W_Mul; package body FZ_Mul is -- Comba's multiplier. procedure FZ_Mul_Comba(X : in FZ; Y : in FZ; XY_Lo : out FZ; XY_Hi : out FZ) is -- Words in each multiplicand L : constant Word_Index := X'Length; -- Length of Product, i.e. double the length of either multiplicand LP : constant Word_Index := 2 * L; -- 3-word Accumulator A2, A1, A0 : Word := 0; -- Register holding Product; indexed from zero XY : FZ(0 .. LP - 1); -- Type for referring to a column of XY subtype ColXY is Word_Index range XY'Range; -- Compute the Nth (indexed from zero) column of the Product procedure Col(N : in ColXY; U : in ColXY; V : in ColXY) is -- The outputs of a Word multiplication Lo, Hi : Word; -- Carry for the Accumulator addition C : WBool; -- Sum for Accumulator addition Sum : Word; begin -- For lower half of XY, will go from 0 to N -- For upper half of XY, will go from N - L + 1 to L - 1 for j in U .. V loop -- Hi:Lo := j-th Word of X * (N - j)-th Word of Y Mul_Word(X(X'First + j), Y(Y'First - j + N), Lo, Hi); -- Now add Hi:Lo into the Accumulator: -- A0 += Lo; C := Carry Sum := A0 + Lo; C := W_Carry(A0, Lo, Sum); A0 := Sum; -- A1 += Hi + C; C := Carry Sum := A1 + Hi + C; C := W_Carry(A1, Hi, Sum); A1 := Sum; -- A2 += A2 + C A2 := A2 + C; end loop; -- We now have the Nth (indexed from zero) word of XY XY(N) := A0; -- Right-Shift the Accumulator by one Word width: A0 := A1; A1 := A2; A2 := 0; end Col; pragma Inline_Always(Col); begin -- Compute the lower half of the Product: for i in 0 .. L - 1 loop Col(i, 0, i); end loop; -- Compute the upper half (sans last Word) of the Product: for i in L .. LP - 2 loop Col(i, i - L + 1, L - 1); end loop; -- The very last Word of the Product: XY(XY'Last) := A0; -- Output the Product's lower and upper FZs: XY_Lo := XY(0 .. L - 1); XY_Hi := XY(L .. XY'Last); end FZ_Mul_Comba; pragma Inline_Always(FZ_Mul_Comba); end FZ_Mul; |
I will omit the detailed analysis of why Comba's Multiplication works, and leave the proof as an exercise for the reader. However, do observe that this routine demands a Mul_Word procedure. Which the reader will correctly guess, lives in the unit W_Mul:
W_Mul.ads:
with Words; use Words; package W_Mul is pragma Pure; -- The bitness of a Half-Word HalfBitness : constant Positive := Bitness / 2; subtype HalfWord is Word range 0 .. 2**HalfBitness; -- The number of bytes in a Half-Word HalfByteness : constant Positive := Byteness / 2; -- Multiply half-words X and Y, producing a Word-sized product function Mul_HalfWord(X : in HalfWord; Y : in HalfWord) return Word; -- Get the bottom half of a Word function BottomHW(W : in Word) return HalfWord; -- Get the top half of a Word function TopHW(W : in Word) return HalfWord; -- Carry out X*Y mult, return lower word XY_LW and upper word XY_HW. procedure Mul_Word(X : in Word; Y : in Word; XY_LW : out Word; XY_HW : out Word); end W_Mul; |
W_Mul.adb ("Iron" Variant):
with W_Shifts; use W_Shifts; package body W_Mul is function Mul_HalfWord(X : in HalfWord; Y : in HalfWord) return Word is begin return X * Y; end Mul_HalfWord; pragma Inline_Always(Mul_HalfWord); -- Get the bottom half of a Word function BottomHW(W : in Word) return HalfWord is begin return W and (2**HalfBitness - 1); end BottomHW; pragma Inline_Always(BottomHW); -- Get the top half of a Word function TopHW(W : in Word) return HalfWord is begin return Shift_Right(W, HalfBitness); end TopHW; pragma Inline_Always(TopHW); -- Carry out X*Y mult, return lower word XY_LW and upper word XY_HW. procedure Mul_Word(X : in Word; Y : in Word; XY_LW : out Word; XY_HW : out Word) is -- Bottom half of multiplicand X XL : constant HalfWord := BottomHW(X); -- Top half of multiplicand X XH : constant HalfWord := TopHW(X); -- Bottom half of multiplicand Y YL : constant HalfWord := BottomHW(Y); -- Top half of multiplicand Y YH : constant HalfWord := TopHW(Y); -- XL * YL LL : constant Word := Mul_HalfWord(XL, YL); -- XL * YH LH : constant Word := Mul_HalfWord(XL, YH); -- XH * YL HL : constant Word := Mul_HalfWord(XH, YL); -- XH * YH HH : constant Word := Mul_HalfWord(XH, YH); -- Carry CL : constant Word := TopHW(TopHW(LL) + BottomHW(LH) + BottomHW(HL)); begin -- Get the bottom half of the Product: XY_LW := LL + Shift_Left(LH + HL, HalfBitness); -- Get the top half of the Product: XY_HW := HH + TopHW(HL) + TopHW(LH) + CL; end Mul_Word; pragma Inline_Always(Mul_Word); end W_Mul; |
Mul_Word, it turns out, is merely a Word*Word -> double-Word "schoolbook" multiplier. And: it is abundantly obvious that it could be replaced with a single IMUL instruction on x86/x86-64. But we won't do this in standard FFA -- recall the design principles from Chapter 1! We will not be "marrying" any particular iron.
A very sharp reader may have already noticed the "problematic" element in the above Mul_Word routine. Namely, Mul_HalfWord as given here creates a danger of timing sidechannel leakage on certain machine architectures!

CPUs widely known to suffer from this "helpful" "optimization" include x86-compatible VIA, old Intels (386, 486), and most of the commonly-met PowerPC and ARM devices. Others archs, as well as obscure implementations of well-known archs, may also belong on this list. (Please write in if you happen to know of one such that I have not listed here.)
If FFA were to continue with the above variant (let's call it iron) of Mul_HalfWord, every machine on which it is put to use would have to be first probed for non-constanttime iron multiplication: every newly-purchased CPU is arguably "guilty until proven innocent". But it turns out that there is a simple and relatively-inexpensive cure for this headache:
W_Mul.adb ("Soft" Variant, non-unrolled):
-- Multiply half-words X and Y, producing a Word-sized product function Mul_HalfWord(X : in HalfWord; Y : in HalfWord) return Word is -- X-Slide XS : Word := X; -- Y-Slide YS : Word := Y; -- Gate Mask GM : Word; -- The Product XY : Word := 0; begin -- For each bit of the Y-Slide: for b in 1 .. HalfBitness loop -- Compute the gate mask GM := 0 - (YS and 1); -- Perform the gated addition XY := XY + (XS and GM); -- Crank the next Y-slide bit into position YS := Shift_Right(YS, 1); -- Advance the X-slide by 1 bit XS := Shift_Left(XS, 1); end loop; -- Return the Product return XY; end Mul_HalfWord; pragma Inline_Always(Mul_HalfWord); |
The above Mul_HalfWord replaces the "iron" multiplication with a miniature version of the Chapter 5 "Egyptian" algorithm. Because there is no multiwordism and no carry calculation, this safe (bitwise logical operations and shifts by one bit are constant-time on all CPUs known to me) alternative to the "leaky" MUL, when implemented in the partially unrolled form as follows -- comes at a cost of a less than 6 percent (see further below) increase in required CPU time(see comments):
W_Mul.adb ("Soft" Variant, unrolled):
-- Multiply half-words X and Y, producing a Word-sized product function Mul_HalfWord(X : in HalfWord; Y : in HalfWord) return Word is -- X-Slide XS : Word := X; -- Y-Slide YS : Word := Y; -- Gate Mask GM : Word; -- The Product XY : Word := 0; -- Performed for each bit of HalfWord's bitness: procedure Bit is begin -- Compute the gate mask GM := 0 - (YS and 1); -- Perform the gated addition XY := XY + (XS and GM); -- Crank the next Y-slide bit into position YS := Shift_Right(YS, 1); -- Advance the X-slide by 1 bit XS := Shift_Left(XS, 1); end Bit; pragma Inline_Always(Bit); begin -- For each bit of the Y-Slide (unrolled) : for b in 1 .. HalfByteness loop Bit; Bit; Bit; Bit; Bit; Bit; Bit; Bit; end loop; -- Return the Product return XY; end Mul_HalfWord; pragma Inline_Always(Mul_HalfWord); |
And now, on the same machine as in previous Chapters, timed and plotted logarithmically:
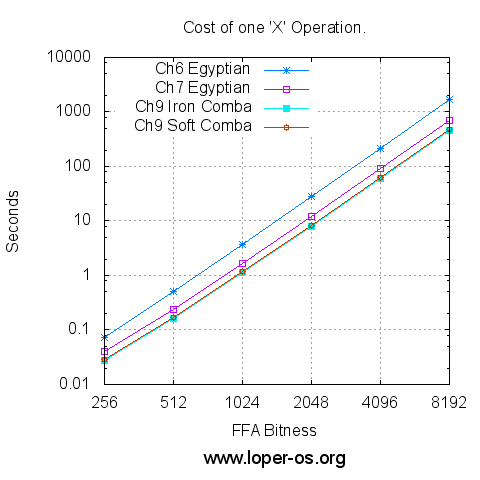
Or, for those who prefer the raw numbers,
| FFA Bitness | Ch.6 Egyptian 'X' (sec) | Ch.7 Egyptian 'X' (sec) | Ch.9 "Iron" Comba 'X' (sec) | Ch.9 "Soft" Comba 'X' (sec) |
|---|---|---|---|---|
| 256 | 0.072 | 0.040 | 0.028 | 0.029 |
| 512 | 0.505 | 0.240 | 0.163 | 0.169 |
| 1024 | 3.685 | 1.672 | 1.125 | 1.177 |
| 2048 | 27.975 | 12.024 | 7.975 | 8.387 |
| 4096 | 217.966 | 90.439 | 59.356 | 62.725 |
| 8192 | 1720.127 | 699.979 | 457.103 | 483.993 |
Despite this small increase in runtime cost, standard FFA will from this point on use only the "soft" variant of Mul_HalfWord, so as to maintain the guarantee of constant-time operation on all known CPU architectures. Individual readers, can, of course, at their own risk -- replace the entirety of Mul_Word -- or even FZ_Mul_Comba -- with an inline-assembly routine known to work safely on a particular CPU. But this type of optimization falls outside the scope of FFA as per the design principles introduced in Chapter 1.
~To be continued!~
Answer to Homework Problem 1 from Chapter 8:
Let's suppose that you wish to test multiplication by generating a Python program via FFACalc. Your tape could look like this:
tape.txt:
??``*[print 0x]##[ == 0x]#[ * 0x]# |
Which would produce a valid Python program that can be fed straight into a Python interpreter, e.g. :
./bin/ffa_calc 1048576 32 /dev/urandom < tape.txt | tr -d '\n' > multest.py |
... will pseudorandomly generate two numbers, each being one megabit in size, and produce a statement regarding their (two-megabit-wide, at most) product, that can be verified by the Python interpreter, in turn producing an output after around half a minute on the test box used thus far.
Now let's feed this output into Python:
$ python < multest.py |
Prints:
True |
... after less than one fifth of a second, on the same machine.
The bulk of the remaining material in this series will concern methods of bridging the speed gap between our routines and traditional "bignum" mechanisms (such as those used in the Python interpreter) to the extent possible without compromising any of the design principles of FFA.
Homework:
1. Prove that Comba's Algorithm works. And in particular, that the three-word Accumulator space given, will always suffice.
2. Given that both "Egyptian" and Comba's multiplication run in O(N^2), why does Comba's method win speedwise? Does it continue to win for all possible operand bitnesses, or only over a particular range?
3. Write an inline assembly variant of FZ_Mul_Comba for your CPU architecture. Demonstrate how you determined that the resulting program, when operating on the exponentiation test tape from Chapter 6, still runs in constant time (i.e. its CPU time cost is unaffected by any aspect of the input other than the choice of FFA bitness) on your particular machine.
~To be continued!~


The rush in preparation of this chapter shows.
The commentary contains a howler.
The impact of replacing hardware multiply by single-word Egyptian multiply is of course much bigger than 6%, but is masked here by the slowness of Egyptian division.
A well.
Dear apeloyee,
The ~6% statement is correct for the measurements given here, which concern the X operation in the particular program of Ch. 9, on the particular test machine. I thought this were obvious ?
I'ma put a pure-MUL comparison in the next Chapter. (Impact on multiplication per se, on my iron, is of course around 6-times, not 6%, yes)
Yours,
-S
Is your captcha broken? I am seeing the folowing text in the box:
V1 UNSUPPORTED Please direct siteowner to g.co/recaptcha/upgrade
but then I get the error: That reCAPTCHA response was incorrect.
And it gives me what looks like a normal captcha?
Dear PeterL,
I have absolutely no idea.
And no intention to "upgrade" any such thing.
The old heathen-powered spamfilter is slated for replacement in the near future; probably with MP's.
Yours,
-S
Yes, captcha sometimes doesn't work, seemingly randomly.
I deal with it the shamanic way (save my comment somewhere else, and refresh the page).
Dear apeloyee,
Indeed, the googlecaptcha thing is liquishit, and I'd like to be rid of it.
This however will involve opening up a gnarly and rusted mechanism I haven't touched for over a decade; thus it will likely have to wait until the end of this series.
Yours,
-S